[ADP 실기 기출 공략] R 프로그래밍 기계 학습 / 모델 설계 및 학습 / 인공신경망
지난 포스팅에서 R을 통한 분류 분석 모델 중 의사결정 나무와 랜덤 포레스트에 대하여 알아보았다.
오늘은 이어서 신경망 모델에 대하여 알아보자.
신경망(Neural Network)은 인간의 뇌를 본 따서 만든 모델이다. 신경망에는 뉴런을 흉내 낸 노드들이 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구분되어 나열된다. 입력층에 주어진 값은 입력층, 은닉층, 출력층 순서로 전달된다.
신경망은 예측 성능이 우수하고, 특히 은닉층에서 입력 값이 조합되므로 비선형적인 문제를 해결할 수 있는 특징이 있다. 그러나, 의사결정 나무 등의 모델과 비교해보면 만들어진 모델을 직관적으로 이해하기가 어렵고 수작업으로 모델을 수정하기도 어려운 단점이 있다.
실습 데이터는 지난 포스팅까지 데이터 전처리 및 파생변수 추가를 완료한 titanic 데이터를 사용한다.
2020/10/21 - [Work/ADP] - [ADP 실기 준비] R 프로그래밍 기계 학습 - 데이터 전처리
[ADP 실기 준비] R 프로그래밍 기계 학습 - 데이터 전처리
[ADP 실기 기출 공략] R 프로그래밍 기계 학습 - 데이터 전처리 새벽녘 바람이 어느덧 제법 쌀쌀해졌다. 따뜻한 봄에 데이터분석 준전문가 ADsP 공부를 시작했는데, 벌써 가을이 성큼 와버렸다. 다
ckmoong.tistory.com
2020/10/28 - [Work/ADP] - [ADP 실기 준비] R프로그래밍 기계 학습 - 탐색적 자료 분석(EDA)
[ADP 실기 준비] R프로그래밍 기계 학습 - 탐색적 자료분석(EDA)
[ADP 실기 기출 공략] R 프로그래밍 기계 학습 / 탐색적 자료 분석(EDA) / 데이터 시각화 지난 포스팅에서 기계 학습을 위한 데이터 전처리 과정 중, 데이터 타입 변환, 결측치 확인 및 처리에 대해서
ckmoong.tistory.com
Contents
1. 신경망 모델 학습
2. 신경망 시각화
3. 성과분석
1. 신경망 모델 학습
우선, 신경망 모델 학습 및 시각화를 위한 패키지들을 다운로드해준다.
# 신경망 R 코드 함수 다운로드
install.packages("nnet")
library(nnet)
# 시각화 R 코드 함수 다운로드
install.packages("devtools")
library(devtools)
source_url('https://gist.githubusercontent.com/fawda123/7471137/raw/466c1474d0a505ff044412703516c34f1a4684a5/nnet_plot_update.r')
# 신경망 모형 시각화
install.packages("reshape2")
library(reshape2)
# 신경망 모델에서 각 변수의 중요도 확인
install.packages("NeuralNetTools")
library(NeuralNetTools)
이제 앞서 분할한 titanic데이터의 train_1 데이터로 nnet함수를 활용한 신경망 모델을 만들어보자.
다음은 nnet 함수 사용법이다.
nnet(formula, data, size, maxit, decay=5e-04)
| 인자 | 설명 |
| formula | 수식 (종속변수 ~ 독립변수) |
| data | 분석하고자 하는 데이터 |
| size | 은닉노드(Hidden Node)의 개수 |
| maxit | 학습 반복횟수, 반복 중 가장 좋은 모델을 선정 |
| decay | 가중치 감소의 모수로 default값은 0이나, 5e-04가 최적으로 알려져있음 |
신경망을 잘 사용하려면 데이터에 정규화를 적용한 뒤 모델을 만들어야 한다.
정규화가 절대적인 의무 사항은 아니지만 정규화를 적용하면 지역 해(local minimum)에 빠질 위험을 피한다.
금번 실습에서는 정규화 과정 없이 titanic 데이터에 대한 신경망 모델을 만들어 보기로 한다.
은닉 노드(Hidden Node)의 개수는 정해진 기준은 없으며, 경험에 의해서 결정해야 하는데 size를 2, 3의 두 경우로 나누어서 모델을 학습시켜 비교해보자.
nnet 함수는 실행할 때마다 값이 다르게 나오기 때문에 재현성을 위해 set.seed() 함수로 설정해준다.
set.seed(1234)
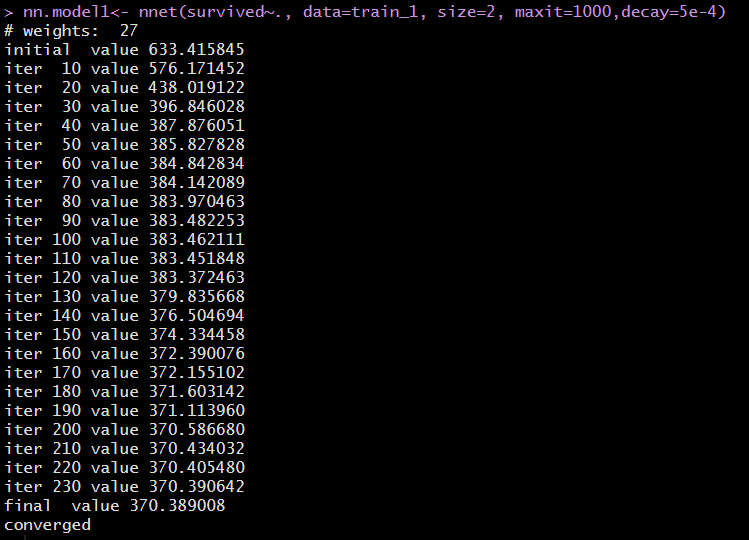
nn.model1<- nnet(survived~., data=train_1, size=2, maxit=1000, decay=5e-4)분석 결과를 확인하면 27개의 가중치가 주어졌고, iteration이 반복될수록 error가 줄어드는 것을 확인할 수 있다.
maxit=1000으로 설정하였지만, 230번째 반복 후에 학습을 멈췄으며, 최종 error 값이 370.389008 임을 final value를 보고 확인할 수 있다.
다음은 은닉 노드의 개수를 3으로 설정하여 신경망 모델을 만들어 보자.
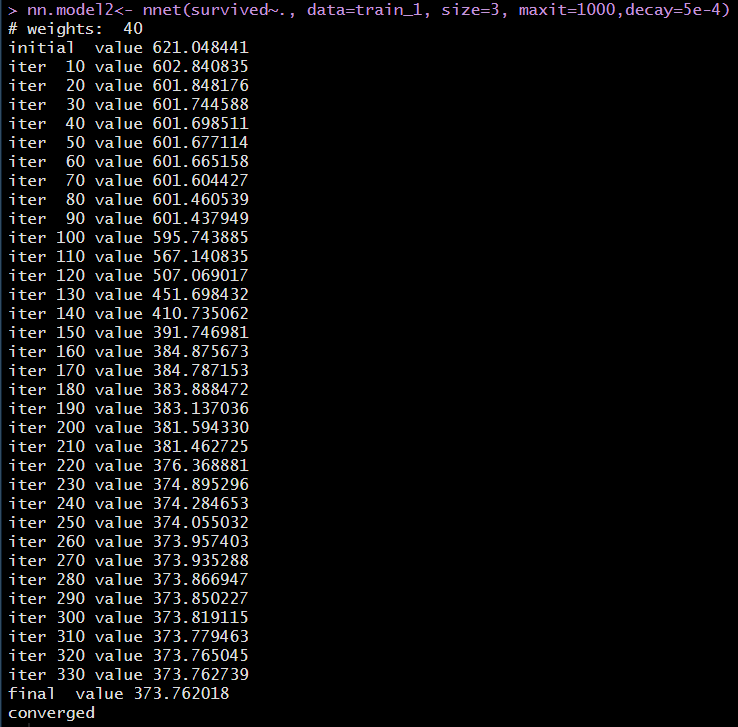
nn.model2<- nnet(survived~., data=train_1, size=3, maxit=1000, decay=5e-4)분석 결과를 확인하면 40개의 가중치가 주어졌고, iteration이 반복될수록 error가 줄어드는 것을 확인할 수 있다.
330번째 반복 후에 학습을 멈췄으며, 최종 error 값이 373.762018 임을 final value를 보고 확인할 수 있다.
summary(nn.model1)summary 함수로 분석 결과를 확인하면 "a 11-2-1 network with 27 weight"는 입력 노드 11개, 은닉노드 2개, 출력노드 1개를 의미하고 가중치는 총 27개임을 알 수 있다.

summary(nn.model2)summary 함수로 분석 결과를 확인하면 "a 11-3-1 network with 40 weight"는 입력노드 11개, 은닉노드 3개, 출력노드 1개를 의미하고 가중치는 총 40개임을 알 수 있다.
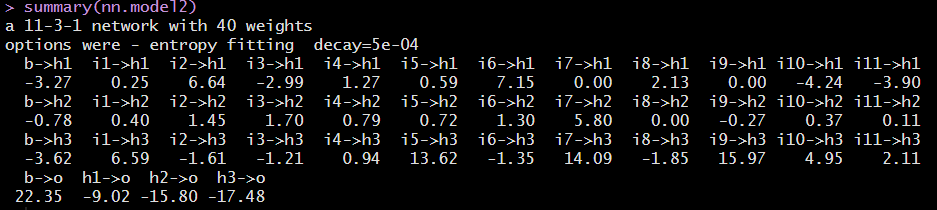
i는 입력노드 h는 은닉 노드, o는 출력 노드, b는 상수항(bias)의 가중치를 나타낸다. 위의 smmary 결과로 해석이 어려우므로 그림으로 나타내 보자.
2. 신경망 시각화
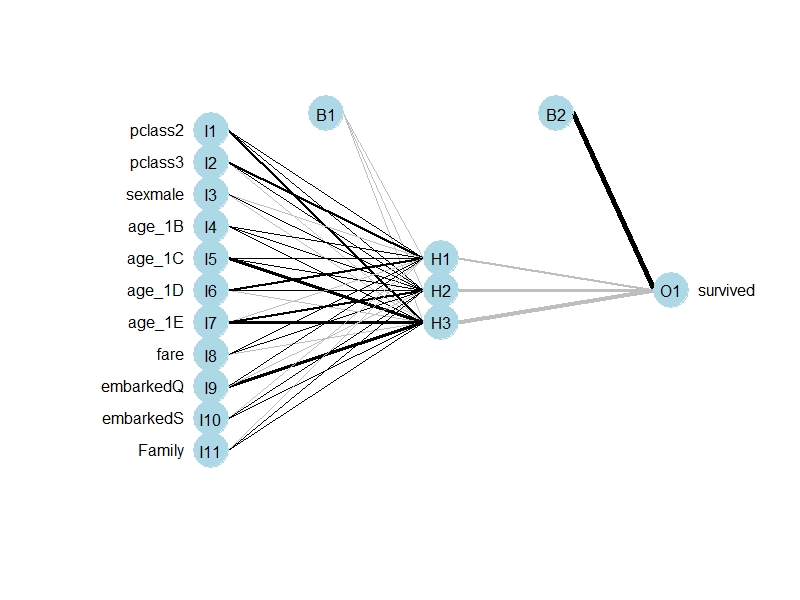
plot.nnet(nn.model1)summary의 결과에서 나타난 것처럼 11개의 입력 노드, 2개의 은닉 노드, 1개의 출력 노드, 2개의 상수항을 확인할 수 있다.
아래 그림에서 선의 굵기는 연결선의 가중치(weight)에 비례한다.
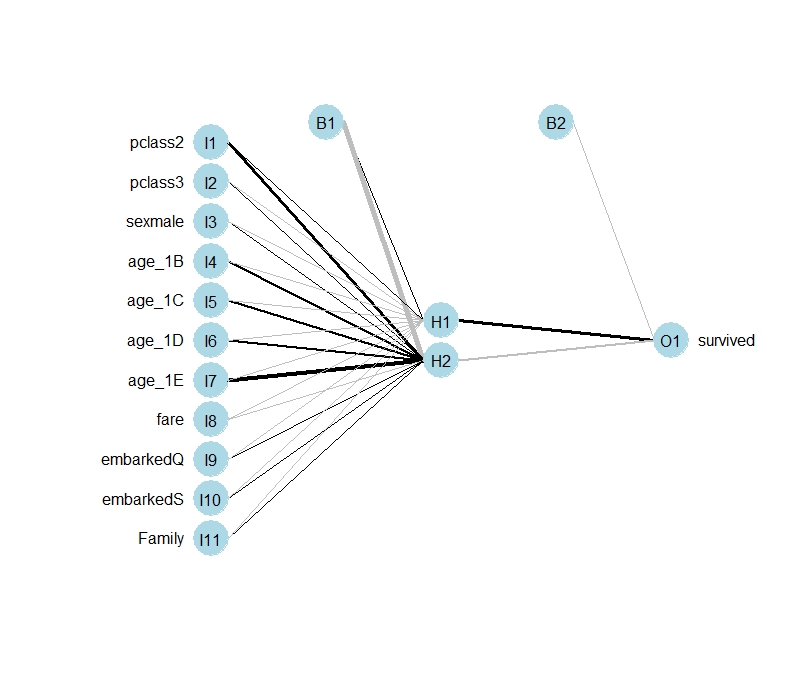
plot.nnet(nn.model2)마찬가지로 summary의 결과에서 나타난 것처럼 11개의 입력노드, 3개의 은닉노드, 1개의 출력노드, 2개의 상수항을 확인할 수 있다.
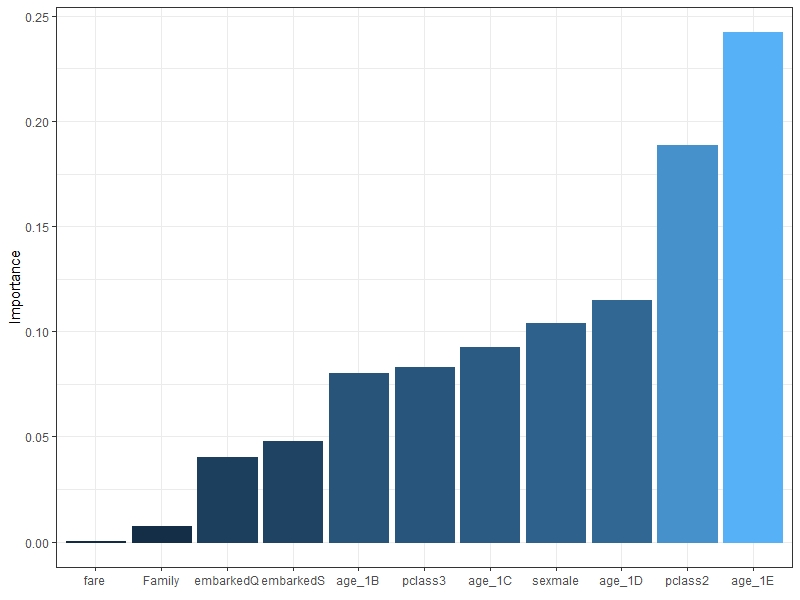
또한, 변수 중요도 그래프를 통해 모델의 부류에서 중요한 변수를 확인할 수 있다.
garson(nn.model1)변수 중요도를 파악한 결과, nn.model1에서는 age_1E, pclass2, age 1 D, sexmale 순으로 변수 중요도가 크다는 것을 파악할 수 있다.
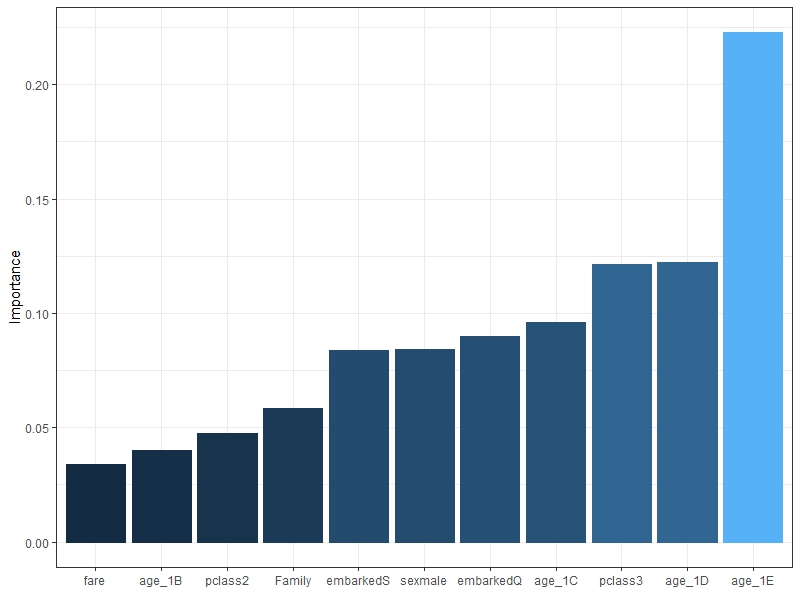
garson(nn.model2)nn.model2에서는 age_1E, age1D, pclass3 순으로 변수 중요도가 크다는 것을 알 수 있다.
3. 성과 분석
각 모델의 성과를 비교하기 위해 예측을 통한 정 분류율을 확인해보자.
성과 분석에 대한 자세한 설명은 이전 포스팅을 참조하시길 바란다.
2020/10/30 - [Work/ADP] - [ADP 실기 준비] R 기계 학습 - 분류 분석 모델링 및 성과 분석
[ADP 실기 준비] R 기계 학습 - 분류분석 모델링 및 성과 분석
[ADP 실기 기출 공략] R 프로그래밍 기계 학습 / 파생 변수 추가 /모델 설계 및 학습 / 의사결정 나무 / 랜덤 포레스트 이번에는 데이터 탐색 및 시각화에 이어 파생변수 추가와 모델 설계 및 학습
ckmoong.tistory.com
pred.nn1 <-as.factor(predict(nn.model1, test_1[,-2],type="class"))
confusionMatrix(data=pred.nn1, reference=test_1[,2],positive='survived')정 분류율(Accuracy)은 0.7679이며, 민감도(Sensitivity)는 0.5364로 나타났다.
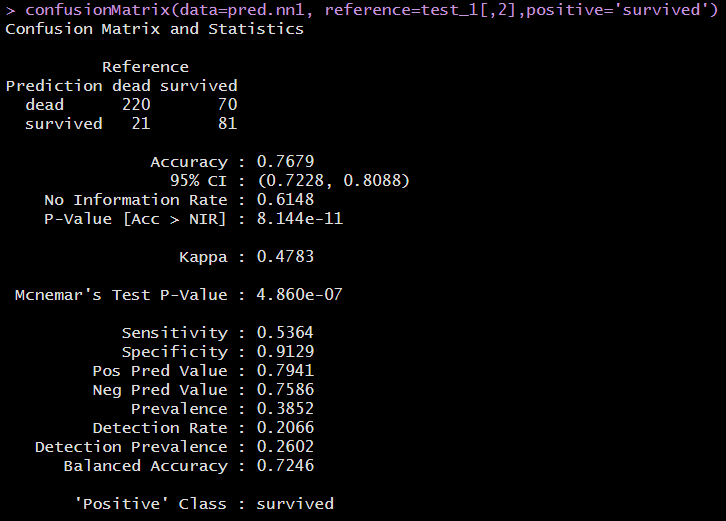
pred.nn2 <-as.factor(predict(nn.model2, test_1[,-2],type="class"))
confusionMatrix(data=pred.nn2, reference=test_1[,2],positive='survived')정분류율(Accuracy)은 0.7628이며, 민감도(Sensitivity)는 0.5232로 nn.model1보다 성능이 낮게 나타났다.
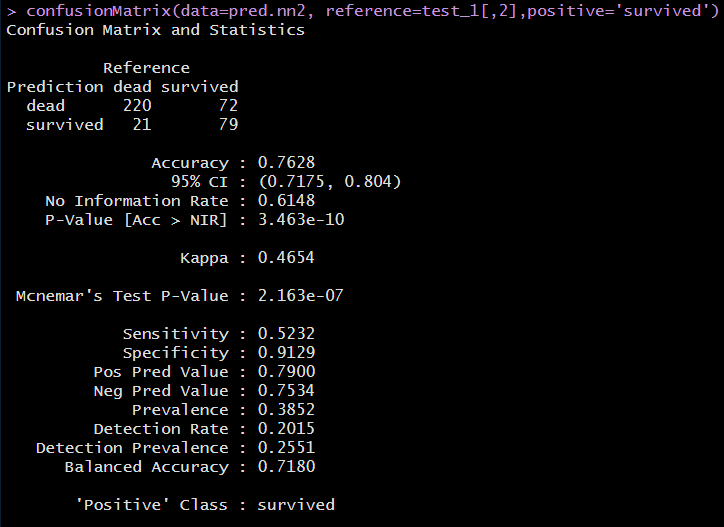
지난번 의사결정 나무 모델의 정 분류율 0.8092, 민감도 0.7027과 비교해보면 매우 낮은 성능을 나타내고 있다.
지금까지 분류 분석을 위한 신경망 모델에 대하여 학습해보았다.
'Work > ADP' 카테고리의 다른 글
| [ADP 실기 준비] R 통계분석 / 선형회귀분석 / 변수선택법 (2) | 2020.11.16 |
|---|---|
| [ADP 실기 준비] R 기계 학습 - 분류분석 모델링 및 성과 분석 (6) | 2020.10.30 |
| [ADP 실기 준비] R프로그래밍 기계 학습 - 탐색적 자료분석(EDA) (2) | 2020.10.28 |
| [ADP 실기 준비] R 프로그래밍 기계 학습 - 데이터 전처리 (8) | 2020.10.21 |
| [ADP 실기 준비] R 시계열 분석 2탄 / ARIMA 모델 / 기출공략 (0) | 2020.10.14 |




댓글