[ADP 실기 기출 공략] R 프로그래밍 기계 학습 - 데이터 전처리
새벽녘 바람이 어느덧 제법 쌀쌀해졌다.
따뜻한 봄에 데이터분석 준전문가 ADsP 공부를 시작했는데, 벌써 가을이 성큼 와버렸다.
다가오는 12월 13일 데이터분석 전문가 ADP 실기를 대비하기 위해, 기존 데이터분석 전문가 ADP 실기시험 기출문제를 찾아서 간단한 데이터 예제로 학습해보려 한다.
참고로, 데이터분석 데이터분석 전문가(ADP) 시험을 접수하는 데이터 자격시험 사이트에 가보면
https://www.dataq.or.kr/
www.dataq.or.kr
상단의 커뮤니티 > 공지사항에 매 회 데이터분석 전문가(ADP) 실기 시험 평가 문항을 사전 공지하고 있다.
(문제는 시험 5일 전에 공지한다;;)
18회차 ADP 실기 시험은 텍스트마이닝, 기계학습, 통계분석 이렇게 3문제가 사전 공지한대로 출제되었다.

제 18회 ADP 기출문제
다음은 18회차 데이터분석 전문가 (ADP) 실기 시험에 출제된 "기계학습" 과목 문제이다.
기계학습은 데이터분석 전문가(ADP) 시험에 거의 매회 출제되고 있으며, 이러한 기계학습을 활용한 분석을 하기 위해서는, "데이터 전처리"가 반드시 필요하다.
오늘은 데이터 전처리 과정 중 "데이터 타입 변환, 결측치 확인 및 처리"에 관해 학습해보려 한다.
기계학습 - 데이터 전처리
[ 데이터 구성 ] Sales data : id, grade, days, count, amount]
1. 결측치(NA)처리, 탐색적 자료분석(EDA), 데이터 시각화(10점)
2. 3개의 파생 변수 생성(10점)
3. Train, test 를 7:3으로 clustering SOM을 사용하여 예측. 그 결과를 confusion Matrix 생성(10점)
4. 랜덤포레스트, 다층 신경망 포함하여 4가지 방법으로 예측 후 그 결과를 F1제시. ROC커브 생성(10점)
예제 : 타이타닉 데이터
타이타닉 데이터는 반더빌트 대학교의 바이오 통계학과 데이터셋 위키 페이지에서 다운로드 할 수 있다.
해당 페이지의 'Data for Titanic passengers' 섹션을 찾아 titanic3.csv 파일을 다운로드 한다.
DataSets < Main < Vanderbilt Biostatistics Wiki
sav ari_other.sav manage 82.2 K 09 Jan 2007 - 17:39 FrankHarrell Sc, Y, Y.death objects for WHO ARI Multicentre Study of Clinical Signs and Etiologic Agents
biostat.mc.vanderbilt.edu
타이타닉 데이터는 CSV 파일 형식으로 되어 있으며, 다음은 사용할 컬럼에 대한 설명이다.
| 컬럼명 | 의미 |
| pclass | 1, 2, 3등석 정보를 각각 1, 2, 3으로 저장 |
| survived | 생존 여부: survived(생존), dead(사망) |
| name | 이름 |
| sex | 성별: female(여성), male(남성) |
| age | 나이 |
| sibsp | 함께 탑승한 형제 또는 배우자 수 |
| parch | 함께 탑승한 부모 또는 자녀 수 |
| ticket | 티켓 번호 |
| fare | 티켓 요금 |
| cabin | 선실 번호 |
| embarked | 탑승한 곳: C(Cherbourg), Q(Queenstown), S(Southampton) |
데이터 불러오기
read.csv()를 사용하여 파일을 읽어들이고, 불필요한 컬럼(boat/body/home.dest) 삭제 후, srt()로 데이터를 살펴본다.
> titanic <- read.csv("titanic3.csv")
> titanic <- titanic[ ,!names(titanic) %in% c("boat","body","home.dest") ]
> str(titanic)
'data.frame': 1309 obs. of 11 variables:
$ pclass : int 1 1 1 1 1 1 1 1 1 1 ...
$ survived: int 1 1 0 0 0 1 1 0 1 0 ...
$ name : chr "Allen, Miss. Elisabeth Walton" "Allison, Master. Hudson Trevor" "Allison, Miss. Helen Loraine" "Allison, Mr. Hudson Joshua Creighton" ...
$ sex : chr "female" "male" "female" "male" ...
$ age : num 29 0.92 2 30 25 48 63 39 53 71 ...
$ sibsp : int 0 1 1 1 1 0 1 0 2 0 ...
$ parch : int 0 2 2 2 2 0 0 0 0 0 ...
$ ticket : chr "24160" "113781" "113781" "113781" ...
$ fare : num 211 152 152 152 152 ...
$ cabin : chr "B5" "C22 C26" "C22 C26" "C22 C26" ...
$ embarked: chr "S" "S" "S" "S" ...
데이터 타입 변환
str(titanic) 결과를 보면 pclass는 1, 2, 3등석이 1, 2, 3인 정수(int)로 표현되어 있다.
그러나, 이들 사이에 사칙연산 관계가 존재하는 것이 아니므로 범주형 변수로 표현하는 것이 좋다.
또한, sex(성별)도 male(남성)과 female(여성) 두 가지로 구분되기에 문자열(chr)에서 팩터(Factor)로 바꿔준다.
embarked(탑승한 곳)도 마찬가지로 팩터로 바꿔준다.
마지막으로, survived는 생존여부를 뜻하므로 팩터로 설정해야 R 기계학습 함수를 호출했을 때
분류(classification) 알고리즘이 수행된다.
만약 정수(int)로 두면 회귀분석을 수행하게 된다.
titanic$pclass <- as.factor(titanic$pclass)
titanic$sex <- as.factor(titanic$sex)
titanic$embarked <- as.factor(titanic$embarked)
titanic$survived <- factor(titanic$survived, levels=c(0,1), labels=c("dead","survived"))
str(titanic)
str()을 확인해본 결과, 올바른 타입으로 데이터가 저장된 것을 확인할 수 있다.

결측치(NA) 처리
결측치는 말 그대로 데이터에 값이 없는 것을 뜻한다. 줄여서 'NA(Not Available)'라고 표현하기도 한다.
결측치는 데이터 분석에 방해가 되는 존재이며, 아래와 같은 문제를 불러올 수 있다.
- 결측치를 제거할 경우, 데이터 손실을 야기할 수 있다.
- 결측치를 잘못 대체할 경우, 데이터의 편향(bias)을 일으킬 수 있다.
따라서, 결측치를 처리함에 있어 분석가의 정확한 견해가 반영되어야 하고 그러기 위해서는 결측치 처리를 위해 많은 시간이 투자되어야 하는 경우도 발생한다.
무엇보다, 데이터에 기반한 결측치 처리야말로 정확한 분석을 위한 첫 걸음이라고 할 수 있겠ㅂ다.
결측치 확인
1. str() 로 Factor의 결측치 확인하기
위의 str() 요약결과를 확인해보면, embarked 변수에 " "로 비어있는 것을 확인할 수 있다.
이 값에 대하여 확인해보자.
> levels(titanic$embarked)
[1] "" "C" "Q" "S"
> table(titanic$embarked)
C Q S
2 270 123 914
" "값이 2개 존재하고 있음을 알 수 있다.
read.csv()가 CSV파일을 그대로 불러들이는 점을 생각해보면, 빈 문자열 " "은 NA를 의미함을 알 수 있다.
" "를 NA로 수정한다.
> levels(titanic$embarked)[1] <- NA #1열인 " "를 NA로 변환
> table(titanic$embarked, useNA="always") #useNA="always는 NA 개수도 출력
C Q S <NA>
270 123 914 2
마지막으로 str()을 사용하여 데이터가 올바르게 변경되었는지 확인한다.
embarked 변수가 3 level로 잘 변경된 것을 확인할 수 있다. *결측치(NA)는 팩터의 level에 표시되지 않음

2. View() 로 결측치 확인하기
데이터를 화면으로 편리하게 탐색하는 한 가지 방법은,
환경창에서 데이터셋을 클릭하거나 View(titanic) 명령을 사용하는 것이다.
화면을 눈으로 쓰윽~ 확인해보면, 어느 변수에서 결측치가 있는지 대략적으로 빠르게 알 수 있다.

3. diagnose() 로 결측치 확인하기
dlookr 은 탐색적 데이터분석(EDA)을 지원하는 패키지다.
이 패키지는 dplyr 패키지와 협업하여 데이터를 탐색 및 조작할 수 있는 기능을 제공한다.
> install.packages("dlookr") #패키지 설치
> library(dlookr)
> diagnose(titanic)
diagnose() 는 데이터프레임의 변수를 진단하며, 반환하는 객체의 변수는 다음과 같다.
- variables : 변수명
- types : 변수의 데이터 유형
- missing_count : 결측치 수
- unique_count : 유일값의 수
- unique_rate : 유일값의 비율 (=unique_count/관측치 수)

diagnose() 결과를 보면, age변수에 결측치가 263개, embarked변수에 결측치가 2개 존재한다.
참고로, name변수의 unique_count는 1307로 전체 1309명 중 이름이 같은 사람이 2명 있다는 것을
유추해볼 수 있겠다.
통상적으로 unique_count나 unique_rate가 1인 변수는 식별자일 확률이 크므로 분석모델의 변수로 적합하지 않다.
여기서는 name변수가 unique_rate가 0.998로 1에 가까우므로 분석모델에 적합치 않은 변수다.
4. naniar() 로 결측치 확인하기
naniar 는 결측치를 다루는 외부 패키지이다.
데이터셋에 포함된 결측치 현황을 입체적으로 파악할 수 있다.
> install.packages("naniar")
> library(naniar)
> n_miss(titanic) #결측치(NA) 갯수
[1] 266
> miss_var_summary(titanic) #변수별 결측치(NA) 현황

> vis_miss(titanic) #결측치(NA) 패턴 시각화
위의 출력된 결과와 아래 그래프를 보면, age변수에 263개(20.09%)의 결측치가 존재함을 확인할 수 있다.
또한, embarked변수와 fare변수도 각각 2개(0.15%), 1개(0.1%미만)의 결측치가 존재하고 있다.

5. apply() 로 결측치 확인하기
apply() 는 행 또는 열 별로 함수를 적용하여 한 번에 결과를 산출해주는 함수이다.
apply() 와 사용자 정의 함수를 이용하여 titanic 데이터의 모든 변수에 대해 각각 결측치(NA) 갯수를 확인할 수 있다.
> apply(titanic,2,function(x) sum(is.na(x))) #2는 변수 열별로 함수를 적용
#sum(is.na(x))는 x데이터에 존재하는 NA값 개수의 합계를 구함

지금까지 데이터의 결측치를 쉽게 확인할 수 있는 5가지 방법에 대해 알아보았다.
이 외에도 다른 패키지나 조건을 활용하여 다양한 방식으로 결측치를 확인할 수 있다.
결측치를 확인했으면, 이제 그 결측치를 처리하는 방법에 대해 알아보겠다.
결측치 제거
1. complete.cases()
데이터에서 모든 변수값 중 특정 행에 결측치가 하나라도 존재하는 경우,
해당 행을 제거한 후 데이터 분석을 진행하고자 할 때 결측치 제거를 수행한다.
complete.cases()를 사용하여 결측치가 없는 완전한 행들로만 데이터를 재구성해준다. (=결측치 제거)
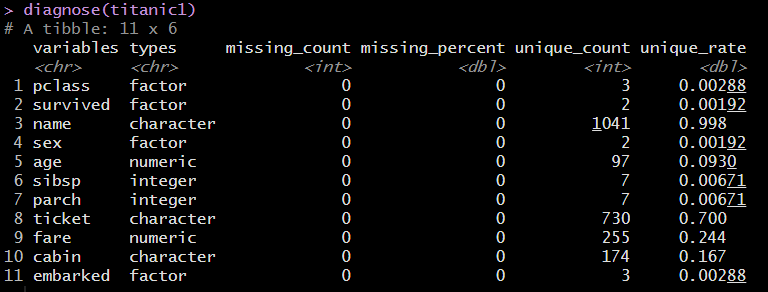
> titanic1 <- titanic[complete.cases(titanic),]
> diagnose(titanic1)
diagnose()로 결측치가 제거된 것을 확인할 수 있다. (=missing_count가 전부 zero)
2. na.omit()
na.omit()은 인자로 지정한 데이터프레임에서 결측치가 존재하는 행을 제외시켜주는 함수이다.
> titanic2 <- na.omit(titanic)
> diagnose(titanic2)
complete.cases()의 결과와 동일한 결과를 보여준다.

3. 특정 변수의 결측치 행만 삭제
실제 결측치가 많은 데이터를 분석하는 경우, 결측치를 전부 삭제해버리면 데이터의 손실이 많아져
데이터 분석결과에도 좋지 않은 영향을 미치는 경우가 많다.
따라서, 매우 적은 수의 결측치가 존재하는 변수에서는 결측치를 삭제하고
결측치가 많은 데이터는 분석가의 견해를 반영하여 결측치를 대체해주는 편이 좋다.
complete.cases()를 사용하여 결측치가 2개, 1개 존재하는 9열(fare)과 11열(embarked) 변수의 결측치를 제거한다.
> titanic <- titanic[complete.cases(titanic[ ,9]), ]
> titanic <- titanic[complete.cases(titanic[ ,11]), ]
결측치 대체
앞에서 fare변수와 embarked변수의 결측치를 제거하였다.
age변수는 결측치가 263개로 전체 데이터의 약 20.1%를 차지하기 때문에,
제거보다는 대체를 통해 데이터 분석을 진행하는 것이 좋다.
가장 기본적인 결측치 대체 방법은 다음과 같다.
- 수치형 변수 : 평균으로 대체
- 범주형 변수 : 최빈값으로 대체
하지만, 무턱대고 결측치를 대체하는 경우 데이터가 심하게 쏠릴 수도 있으니 항상 다음 사항을 확인해야 한다.
- 전체 데이터 대비 결측치가 차지하는 비율(%)
- 결측치가 포함된 변수의 데이터 분포
- 결측치가 포함된 변수와 다른 변수들과의 관계 유무
데이터의 분포가 정규분포의 형태라면 평균값으로 대체하여도 무방하지만,
그렇지 않은 경우는 평균보다는 중위수가 안정적이다. 중위수는 극단값(Outlier)에 영향을 덜 받기 때문이다.
물론 중위수로 대체하는 것이 항상 최선의 방법은 아니며,
때로는 다른 변수와의 관계를 확인하여 더 정교한 방법을 찾아야한다.
titanic 데이터에서 age변수의 데이터 분포를 확인해보자.
> install.packages("ggplot2")
> library(ggplot2)
> summary(titanic$age)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.17 21.00 28.00 29.88 39.00 80.00 263
> ggplot(titanic,aes(x=age)) + geom_histogram(fill='royalblue') + ylab('') + xlab("age")
분포 그래프를 보면, age변수는 정규분포의 형태를 띠는 것을 알 수 있다.
summary(titanic$age)를 통해 평균값(Mean)과 중위수(Median)의 차이를 확인해보아도 28.00과 29.88로 큰 차이는 없다.
따라서, age변수의 결측치를 평균값으로 대체해도 무방할 것으로 판단된다.

1. imputate_na()
결측치를 대체하는 다양한 패키지와 방식이 있겠으나, 앞서 결측치 확인에 사용한 dlookr 패키지를 사용해보려 한다.
dlookr 패키지의 imputate_na() 는 변수에 포함된 결측치를 대체한다.
결측치가 포함된 변수는 수치형 변수와 범주형 변수 모두 아래와 같이 지원한다.

위의 age변수는 수치형 변수이므로, imputate_na()는 mean 방법으로 결측치를 대체해본다.
summary()는 결측치 대체 정보를 요약해주고, plot()은 결측정보를 시각화해준다.
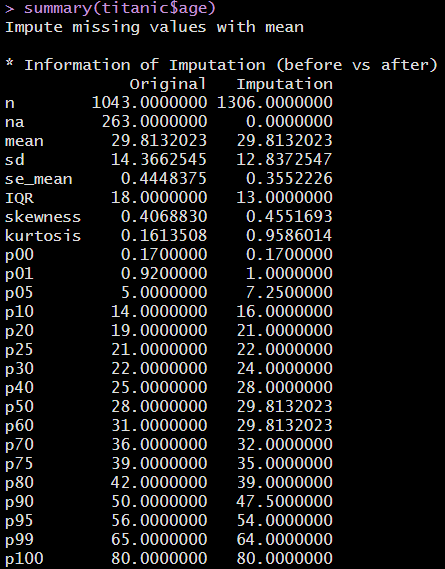
> titanic$age <- imputate_na(titanic, age, method = "mean") #age변수의 결측치를 평균으로 대체
> summary(titanic$age) #변수열 대체 확인
아래와 같이 263개의 결측치(na)가 데이터의 중위수(중앙값)로 대체된 것을 확인할 수 있다.
참고로, rpart를 이용한 대체를 사용하려면 "문자열" 타입의 변수를 변환 및 제거한 후에 사용해야 한다.
> plot(titanic$age)
아래 그래프에서 녹색선은 원본 데이터의 밀도 그래프이고, 붉은선은 결측치를 평균으로 대체한 후의 밀도 그래프이다.
263개의 결측치를 평균으로 대체했기 때문에, 평균값 부분의 밀도가 높아진 것을 볼 수 있다.
다시 말하지만, 결측치를 대체하는 방법을 선택하는 것은 데이터를 분석하는 분석가의 견해가 중요하다.

diagnose()를 사용하여 점검해보면, 모든 결측치가 처리된 것을 확인할 수 있다.

2. DMwR 패키지 활용
> titanic <- centralImputation(titanic) #결측치를 중위수(중앙값)로 대체
> diagnose(titanic)
imputate_na()의 median 방법과 동일한 방법으로서
diagnose()를 통해 결측치가 처리된 것을 확인할 수 있다.

지금까지 기계학습을 위한 데이터 전처리 과정 중 데이터 변환, 결측치 확인 및 처리에 관해 알아보았다.
'Work > ADP' 카테고리의 다른 글
| [ADP 실기 준비] R 기계 학습 - 분류분석 모델링 및 성과 분석 (6) | 2020.10.30 |
|---|---|
| [ADP 실기 준비] R프로그래밍 기계 학습 - 탐색적 자료분석(EDA) (2) | 2020.10.28 |
| [ADP 실기 준비] R 시계열 분석 2탄 / ARIMA 모델 / 기출공략 (0) | 2020.10.14 |
| [ADP 실기 준비] R 시계열 분석 (0) | 2020.10.11 |
| 제 18회 ADP(데이터분석 전문가) 필기/독학/합격 후기 (83) | 2020.10.09 |




댓글