[ADP 실기 기출 공략] R 프로그래밍 기계 학습 / 탐색적 자료 분석(EDA) / 데이터 시각화
지난 포스팅에서 기계 학습을 위한 데이터 전처리 과정 중, 데이터 타입 변환, 결측치 확인 및 처리에 대해서 알아보았다.
아래에 지난 시간에 진행한 코딩을 간단하게 요약하였다.
titanic <- read.csv("titanic3.csv") #데이터 불러오기
titanic <- titanic[ ,!names(titanic) %in% c("boat","body","home.dest") ] #불필요한 변수 제거
titanic$pclass <- as.factor(titanic$pclass) #데이터 타입 변환
titanic$sex <- as.factor(titanic$sex)
titanic$embarked <- as.factor(titanic$embarked)
titanic$survived <- factor(titanic$survived, levels=c(0,1), labels=c("dead","survived"))
levels(titanic$embarked)[1] <- NA #빈칸 NA로 대치
install.packages(dlookr) #패키지 설치
library(dlookr) #패키지 로딩
diagnose(titanic) #결측치 확인
titanic$age <- imputate_na(titanic, age, method = "mean") #결측치 대치
titanic <- titanic[complete.cases(titanic[ ,9]), ] #결측치 제거
titanic <- titanic[complete.cases(titanic[ ,11]), ] #결측치 제거
이번에는 기계학습 분류 모델을 구축하기 전, 데이터 탐색 및 시각화 과정에 대하여 알아볼 것이다.
기계학습 모델을 작성하기 전에 데이터가 어떤 형태의 모습을 하고 있는지 살펴보면, 어떤 방법으로 모델을 만들지에 대한 아이디어를 얻을 수 있다.
또한, 데이터를 불러들일 때 에러의 발생 유무도 이 단계에서 알 수 있다.
Contents
1. 데이터 탐색
1-1. summary()
1-2. describe()
2. 시각화
2-1. featurePlot()
2-2. mosaicplot()
1. 데이터 탐색
1-1. summary
summary()는 데이터에 대한 간략한 분포 정보를 알려주는 함수다.
수치형 변수는 최소, 최대, 평균 등 분포에 대한 기술 통계를 보여주고, 범주형 변수는 항목별 카운트, 문자열 변수는 전체 카운트 값을 보여준다.
summary(titanic)
또한, summary() 내에 함수를 지정해 survived가 pclass, sex, age, sibsp 등의 변숫값들에 따라 어떻게 달라지는지 요약 정보를 살펴보는 방법도 있다.
method="reverse"는 종속 변수 survived에 따라 독립 변수들을 분할하여 보여준다.
표를 통해 각 변숫값에 따라 생존율의 분포가 어떻게 달라지는지 확인할 수 있다.
*수치형 변수의 경우, dead/survived 각각의 사분위(1Q/중위수/3Q) 값을 보여준다.
summary(survived ~ pclass + sex + age + sibsp + parch + fare + embarked,
data=titanic, method="reverse")
1-2. describe
Hmisc 패키지의 describe() 함수는 summary()와 유사하지만, 데이터 내의 결측치(NA)의 수, 서로 다른 값(unique)의 수, 데이터의 분포, 합 등 좀 더 다양한 요약 정보를 제시해준다.
library(Hmisc)
describe(titanic)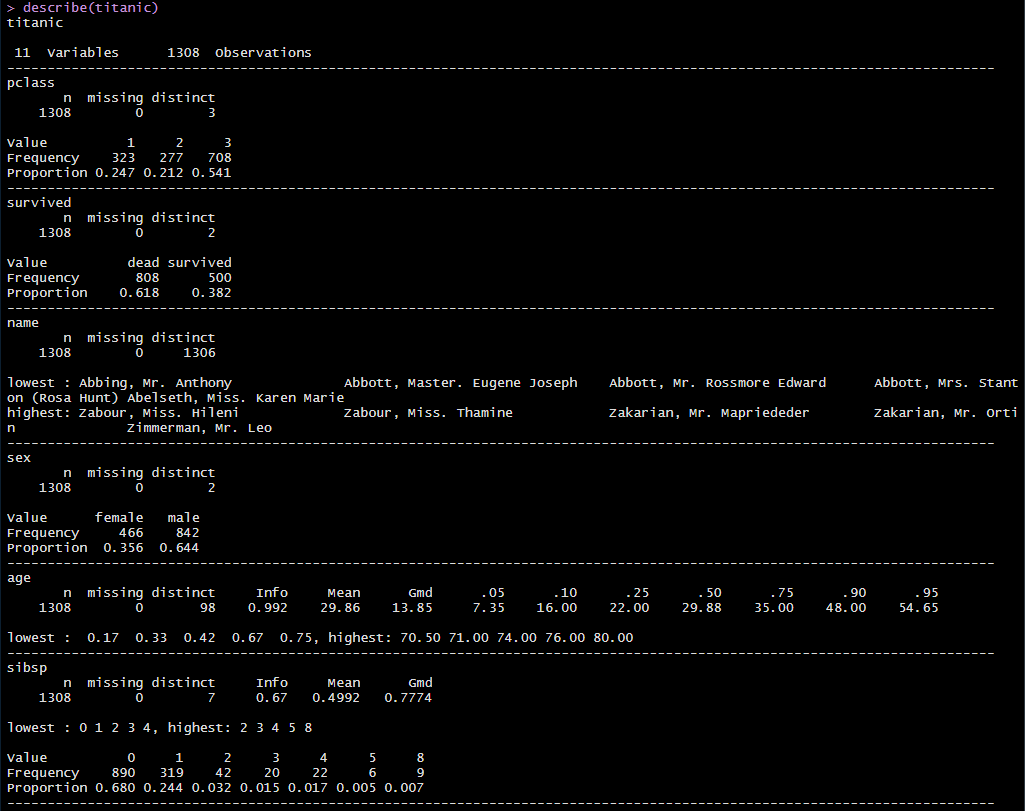
2. 데이터 시각화
2-1. featurePlot()
이번에는 featurePlot()을 사용하여 데이터를 시각화해보자.
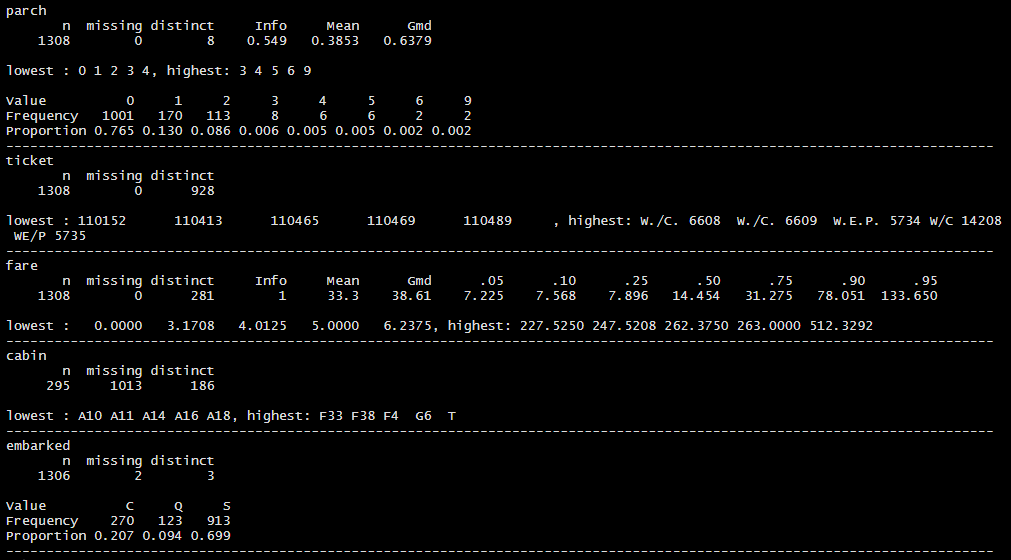
caret 패키지에는 피처와 분류 간의 관련성을 보기 쉽게 시각화해주는 featurePlot() 함수가 있다.
이 함수는 예측 대상이 되는 생존 또는 사망 여부를 y, 예측 변수를 x로 하여 featurePlot()을 호출해준다.
install.packages("caret")
install.packages("ellipse")
library(caret)
library(ellipse)
featurePlot(
titanic[,sapply(names(titanic),
function(x) {is.numeric(titanic[, x])})],
titanic [, c("survived")],
"ellipse")
위의 코드의 설명을 하자면, sapply()에서 names(titanic)은 titanic의 칼럼명들(pclass, survived, name 등)을 반환한다.
sapply는 이 각각의 이름을 function()에 x이라는 이름으로 넘긴다. 호출된 함수는 titanic에서 해당 칼럼이 숫자형 데이터인지 is.numeric()으로 테스트한 후 반환한다.
따라서, sapply()의 최종 결과는 TRUE 또는 FALSE가 저장된 벡터이다. 이 결과가 titanic [, sapply()] 형태로 호출되므로, 숫자 데이터 타입을 저장한 칼럼만 선택된다.
아래 그림을 보면, 생존 유무별로 데이터의 분포를 한눈에 파악할 수 있어 모델 설계에 좋은 출발점이 된다.
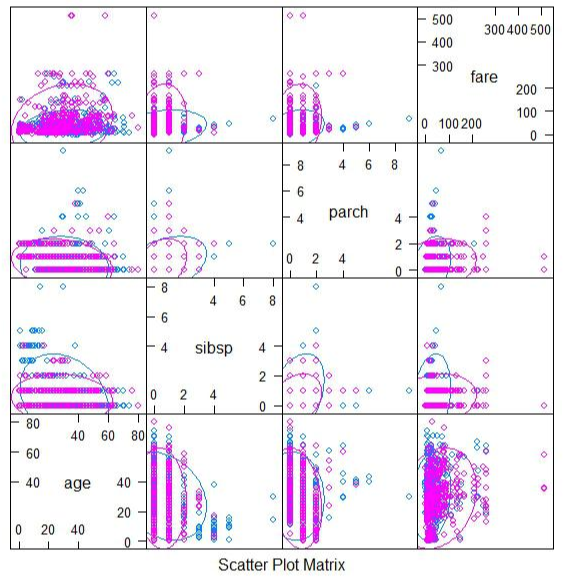
위의 featurePlot() 결과를 보면, 형제나 배우자가(sibsp)가 함께 배에 탔을 경우와 부모나 자식(parch)이 함께 배에 탔을 때 생존한 사람의 비율이 높다는 것을 알 수 있다.
2-2. mosaicplot()
팩터 데이터 타입에는 모자이크 플롯을 사용할 수 있다.
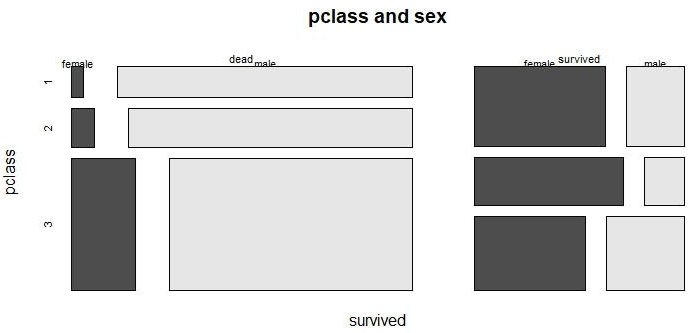
pclass, sex에 따라 생존 여부가 어떻게 달라지는지 확인해본다.
mosaicplot(survived ~ pclass + sex,data=titanic, color=TRUE, main="pclass and sex")실행 결과를 보면, pclass 3, male인 경우(3등석 남성) 사망자가 가장 많고, pclass 1, female(1등석 여성)인 경우 사망자가 가장 적은 것을 확인할 수 있다.
하지만, 여기서의 값은 탑승자 대비 사망률이 아닌 단순 사망 또는 생존자 수임을 유의해야 한다.
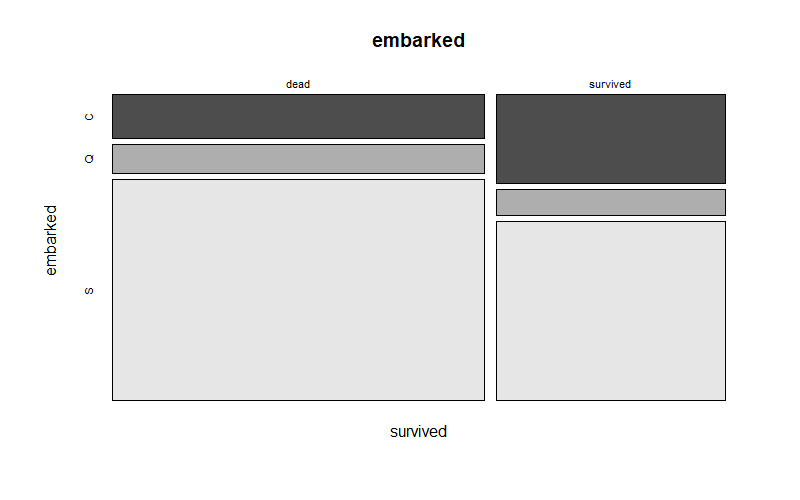
이번에는 어느 선착장에서 배를 탔는지를 나타내는 embarked에 대해 살펴보자.
mosaicplot(survived ~ embarked,data=titanic, color=TRUE, main="embarked")
아래의 결과를 보면, Southampton에서 선착한 사람이 가장 많았으며 Cherbourg에서 탄 사람 중에서는 생존자 비율이 높았고, 나머지 두 선착장에서 탄 사람들은 생존하지 못한 사람이 조금 더 많았다.
지금까지 살펴본 데이터 특성들을 종합해보면,
- 성별이 여자이고
- pclass(티켓의 등급)가 높을수록
- Cherbourg 선착장에서 배를 탔다면
- 형제자매, 배우자, 부모, 자녀와 함께 배를 탔다면
생존 확률이 더 높았다는 것을 알 수 있다.
하지만, 각각의 단일 특성들만 가지고 생존 확률을 예측하기에는 무리가 있다.
예를 들면, pclass가 높은 사람은 부유하기 때문에 가족들과 같이 온 경우가 많다고 가정해본다면
가족들과 함께 왔다고 해서 생존 확률이 높다고 할 수많은 없기 때문이다.
따라서, 단일 특성만 가지고 생존 확률을 예측하기보다는 여러 가지 특성들을 종합해서 예측을 하는 것이 더 바람직할 것이다.
다음 포스팅에서는 파생 변수 생성, 모델 설계 및 학습에 대해서 알아볼 예정이다.
'Work > ADP' 카테고리의 다른 글
| [ADP 실기 준비] R 기계 학습 - 인공신경망 (4) | 2020.11.11 |
|---|---|
| [ADP 실기 준비] R 기계 학습 - 분류분석 모델링 및 성과 분석 (6) | 2020.10.30 |
| [ADP 실기 준비] R 프로그래밍 기계 학습 - 데이터 전처리 (8) | 2020.10.21 |
| [ADP 실기 준비] R 시계열 분석 2탄 / ARIMA 모델 / 기출공략 (0) | 2020.10.14 |
| [ADP 실기 준비] R 시계열 분석 (0) | 2020.10.11 |




댓글